һ�����}�����
�����ڿƌW�о����ճ������У�������Ҫ�Д�ijһ������ͬ������еĺÉġ���(y��u)�ӳ̶ȼ���l(f��)չҎ(gu��)�ɵȆ��}����Ӱ��������������l(f��)չҎ(gu��)�ɵ����أ�ָ�ˣ��Ƕ��ģ���ˣ��ڌ�ԓ�����M���о��r�������ܸ�ȫ�桢�ʴ_�ط�ӳ��������������l(f��)չҎ(gu��)�ɣ��Ͳ����H�Ć�ָ�˻�η���ȥ�u�r�����������]���c�����P�Ķ������أ����о�����Ҫ���������cԓ�������Pϵ��׃�����팦���M�оC�Ϸ������u�r����׃����ӱ��Y�ϟo���ܽo�о��ˆT��Q�����ṩ�ܶ��Ѓrֵ����Ϣ�����ڷ���̎����׃�����}�����ڱ�׃��֮�g��������һ�������P�ԣ�ʹ���^�y��(sh��)��(j��)����ӳ����Ϣ�����دB�F(xi��n)����˞��˱M��������Ϣ�دB�͜p�p���������˂�������ϣ�����ҳ��ٔ�(sh��)�ׂ��������P�ľC��׃�����M���ܵط�ӳԭ�픵(sh��)��(j��)�����еĽ^����Ϣ�������ɷַ��������ӷ������Ǟ��Q����}���a(ch��n)���Ķ�Ԫ�y(t��ng)Ӌ����������
������������@�ɷN�����������(j��ng)�����}�о��еđ���Խ��Խ�࣬�䑪�÷���Ҳ���ӏV�������ӷ��������ɷַ������ƏV�Ͱl(f��)չ������֮�g�̈́ݱ������S�֮ͬ̎���� SPSSܛ������ֱ���M�����ɷַ�������ʹһЩ��������ʹ��SPSS�M���@�ɷN�����ķ����r�����������F(xi��n)һЩ�����Ե��e�`���@�y���ʹ�˂��������Y���a(ch��n)���|�ɡ���ˣ��б�Ҫ���\��SPSS�����r�����@�ɷN�������ԇ���^(q��)�֣���ᘌ����H���}�x�����_�ķ�����
�����������ɷַ����c���ӷ�����(li��n)ϵ�c�^(q��)�e
�����ɷN�����ij��l(f��)�c����׃�������Pϵ��(sh��)��ꇣ��ړpʧ�^����Ϣ��ǰ���£��Ѷ���׃�����@Щ׃��֮�gҪ������^�������P�ԣ��Ա��C��ԭʼ׃������ȡ���ɷ֣��C�ϳ��ٔ�(sh��)�ׂ��C��׃�����о����w��������Ϣ�Ķ�Ԫ�y(t��ng)Ӌ���������@�ٔ�(sh��)�ׂ��C��׃������������Ϣ�����دB����׃���g�����P��
������Ҫ�^(q��)�e��
����1. ���ɷַ�����ͨ�^׃��׃�Q��ע���������ھ����^��׃�����Щ���ɷ��ϣ����ᗉ��Щ׃��С�����ɷ֣����ӷ���������ģ�Ͱ�ע�����������ٔ�(sh��)�����^�y�ĝ���׃�������������ӣ��ϣ����ᗉ�������ӡ�
����2. ���ɷַ����nj����ɷֱ�ʾ��ԭ�^�y׃���ľ��ԽM�ϣ�
������������ �������� ��1��
�������� ��1��
�������ɷֵĂ���(sh��)i=ԭ׃���Ă���(sh��)p������j=1,2,��,p��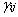 �����P��ꇵ�����ֵ��������������������е�Ԫ�أ� ��ԭʼ׃���Ę˜ʻ���(sh��)��(j��)����ֵ��0�������1���䌍�|��p�S���g������׃�Q������׃ԭʼ��(sh��)��(j��)�ĽY����
�����P��ꇵ�����ֵ��������������������е�Ԫ�أ� ��ԭʼ׃���Ę˜ʻ���(sh��)��(j��)����ֵ��0�������1���䌍�|��p�S���g������׃�Q������׃ԭʼ��(sh��)��(j��)�ĽY����
���������ӷ����t�nj�ԭ�^�y׃���ֽ�ɹ������Ӻ��������Ӄɲ��֡�����ģ����ʽ��2����
������������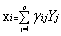 ����������2��
����������2��
��������i=1,2,��,p, m<p ��m�ǹ������ӂ���(sh��)��p��ԭʼ׃������(sh��)���� �����ӷ����^���еij�ʼ�����d�ɾ���е�Ԫ��,
�����ӷ����^���еij�ʼ�����d�ɾ���е�Ԫ��, 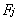 �ǵ�j���������ӣ�
�ǵ�j���������ӣ�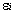 �ǵ�i��ԭ�^�y׃�����������ӡ��Ҵ�̎��
�ǵ�i��ԭ�^�y׃�����������ӡ��Ҵ�̎�� �c�ľ�ֵ����0�������1��
�c�ľ�ֵ����0�������1��
����3. ���ɷֵĸ�ϵ��(sh��)����Ψһ�_���ġ������ġ������Ԍ�ϵ��(sh��)����M���κε����D����ϵ��(sh��)��С��������ԭ׃���c���ɷֵ����P�̶ȣ�������ģ�͵�ϵ��(sh��)����Dz�Ψһ�ġ������M�����D�ģ���ԓ��ꇱ�����ԭ׃���������ӵ����P�̶ȡ�
����4. ���ɷַ���������ͨ�^���^�y��ԭ׃��Xֱ��������ɷ�Y�������п����ԣ����ӷ����е��d�ɾ���Dz�����ģ�ֻ��ͨ�^���^�y��ԭ׃��ȥ��Ӌ�����^�y�Ĺ������ӣ����������ӵ÷ֵĹ�Ӌֵ�������ӵ÷�ϵ��(sh��)����cԭ�^�y׃���˜ʻ���ľ����˵ĽY����߀�У����ɷַ��������������ӷ����ǘ��M���������D̎����
����5.�C�����������ɷַ���һ������(j��)��һ���ɷֵĵ÷�����������һ���ɷֲ�����ȫ����ԭʼ׃�����t��Ҫ�^�m(x��)�x��ڶ������ɷ֡��������ȵȣ��˕r�C�ϵ÷�=�ƣ������ɷֵ÷֡������ɷ��������ķ���ؕ�I�ʣ�,���ɷֵ÷��nj�ԭʼ׃���Ę˜ʻ�ֵ���������ɷֱ��_ʽ��Ӌ��õ��������ӷ����ľC�ϵ÷�=�ƣ������ӵ÷֡��������������ķ���ؕ�I�ʣ��¡Ƹ����ӵķ���ؕ�I�ʣ����ӵ÷��nj�ԭʼ׃���Ę˜ʻ�ֵ���������ӵ÷ֺ���(sh��)��Ӌ��õ���
�����^(q��)�e�д�(li��n)ϵ��(li��n)ϵ���@�^(q��)�e
�������������ᵽ���ɷֿɱ�ʾ��ԭ�^�y׃���ľ��ԽM�ϣ���ϵ��(sh��)��ԭʼ׃�����P��ꇵ�����ֵ���������������������@Щ����������������ˣ���X��Y���D�Q�Pϵ�ǿ���ģ���õ����µ��Pϵ��
������������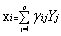 �������� ��3��
�������� ��3��
�������挦��ֻ����ǰm�����ɷ֣�ؕ�I���ᗉʣ��ؕ�I��С�����ɷ֣��ã�
������������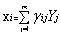 ��������i=1,2,...p������������4��
��������i=1,2,...p������������4��
�����ɴ˿�Ҋ��ʽ��4������ʽ���ѽ�(j��ng)�c����ģ�ͣ�2�������������Ӻ��ģ�ͼ���
������������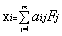 �������� ��2��*
�������� ��2��*
������һ�£���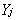 ��j=1,2,��,m��֮�g�����������ģ�ͣ�2��*�����ӷ�����δ�M�������d�����D�r������ģ�ͣ���������M�������d�����D���S�������ߌ����װѴ˕r�����ӷ�����������ɷַ������@�@Ȼ�Dz����_�ġ�
��j=1,2,��,m��֮�g�����������ģ�ͣ�2��*�����ӷ�����δ�M�������d�����D�r������ģ�ͣ���������M�������d�����D���S�������ߌ����װѴ˕r�����ӷ�����������ɷַ������@�@Ȼ�Dz����_�ġ�
����Ȼ���˕r�����ɷֵ�ϵ��(sh��)ꇼ����������c�����d�ɾ�ꇴ_�����������Pϵ��
�������ɷַ����У����ɷֵķ������ԭʼ��(sh��)��(j��)���P��ꇵ�����������˜ʲ�Ҳ����������ƽ����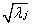 �����ǿ��Ԍ�������˜ʲ��λ�������D���ɺ��m�Ĺ����ӣ�����
�����ǿ��Ԍ�������˜ʲ��λ�������D���ɺ��m�Ĺ����ӣ�����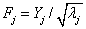 ��
��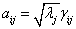 ���tʽ��4��׃?y��u)�?br style="FONT-SIZE: 14px; FONT-FAMILY: ܛ�ź�; WHITE-SPACE: normal; WORD-SPACING: 0px; TEXT-TRANSFORM: none; FONT-WEIGHT: normal; COLOR: rgb(85,85,85); PADDING-BOTTOM: 0px; FONT-STYLE: normal; TEXT-ALIGN: left; PADDING-TOP: 0px; PADDING-LEFT: 0px; ORPHANS: 2; WIDOWS: 2; MARGIN: 0px; LETTER-SPACING: normal; PADDING-RIGHT: 0px; BACKGROUND-COLOR: rgb(255,255,255); TEXT-INDENT: 0px; font-variant-ligatures: normal; font-variant-caps: normal; -webkit-text-stroke-width: 0px"/>
���tʽ��4��׃?y��u)�?br style="FONT-SIZE: 14px; FONT-FAMILY: ܛ�ź�; WHITE-SPACE: normal; WORD-SPACING: 0px; TEXT-TRANSFORM: none; FONT-WEIGHT: normal; COLOR: rgb(85,85,85); PADDING-BOTTOM: 0px; FONT-STYLE: normal; TEXT-ALIGN: left; PADDING-TOP: 0px; PADDING-LEFT: 0px; ORPHANS: 2; WIDOWS: 2; MARGIN: 0px; LETTER-SPACING: normal; PADDING-RIGHT: 0px; BACKGROUND-COLOR: rgb(255,255,255); TEXT-INDENT: 0px; font-variant-ligatures: normal; font-variant-caps: normal; -webkit-text-stroke-width: 0px"/>
������������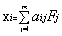 ����������4��*
����������4��*
�����ɵã���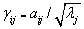 ����������5��
����������5��
����ʽ��5���������ɷ�ϵ��(sh��)����c��ʼ�����d���֮�g��(li��n)ϵ�����ܺ��ε،���ʼ�����d�ɾ���J�������ɷ�ϵ��(sh��)��ꇣ�����������ꇣ�����t�����ƫ�
�����������C����
����ͨ�^�������о�SPSSܛ���е����ӷ��������ɷַ��������߷����Y���ı��^���\�ÃɷN����������2005�꽭�Kʡ13����Ҫ���еĽ�(j��ng)���l(f��)չ�C��ˮƽ�M�з�����
�����������xȡָ�˕r��ѭ��ָ���xȡ�Ļ���ԭ�t����ᘌ��ԡ��ɲ����ԡ��Ӵ��ԡ�ȫ���Ե�ԭ�t���xȡ�����·�ӳ���н�(j��ng)���l(f��)չ�C��ˮƽ��9�ָ�ˣ� GDP(X1)�|Ԫ ���˾�GDP (X2) Ԫ �����(zh��n)�����˾���֧������(X3)Ԫ���r(n��ng)���������(X4) Ԫ�������a(ch��n)�I(y��)ռGDP����(X5)%�����ڙC��������~��X6���|Ԫ���f���и����I(y��)���g�ˆT��(sh��)(X7)�ˡ��Ƽ���헺��Ľ̿��l(w��i)֧����X8���|Ԫ�����H�������Y(X9) �|��Ԫ��
����



